MoE模型大火,源2.0-M32詮釋“三個臭皮匠,頂個諸葛亮”!互聯網+
實測萬興“天幕”:視頻連貫性可圈可點,本土內容優勢顯著
文 | 智能相對論
作者 | 陳泊丞
近半年來,MoE混合專家大模型徹底是火了。
在海外,OpenAI的GPT-4、谷歌的Gemini、Mistral AI的Mistral、xAI的Grok-1等主流大模型都采用了MoE架構。而在國內,浪潮信息也剛剛發布了基于MoE架構的“源2.0-M32”開源大模型。
為什么MoE大模型備受矚目,并逐步成為AI行業的共識?
知名科學雜志《Nature》在今年發表了一篇關于大模型未來發展之路的文章,《In Al, is bigger always better?》(人工智能,越大型越好?)。爭議的出現,意味著AI的發展方向出現了分歧。
如今,“大”不再是模型的唯一追求,綜合應用需要關注模型本身的計算效率和算力開銷兩大問題成為新的行業焦點。
浪潮信息人工智能首席科學家吳韶華在與「智能相對論」交流時也強調,事實上他們當前做的,是在模型能力持續提升的情況下,盡可能降低它的算力開銷。因為今天大模型本身就是由兩個主要因素來決定的,一個是模型能力,一個是算力開銷。

浪潮信息人工智能首席科學家吳韶華
因此,MoE大模型的盛行,實際上對應的正是模型能力和算力開銷兩大問題的解決。這也是為什么眾多大模型廠商如OpenAI、谷歌、Mistral AI、浪潮信息等陸續基于MoE架構升級自家大模型產品的原因。
MoE模型大火的背后,需要厘清三點認知
一、解題思路的轉變:三個“臭皮匠”,頂個“諸葛亮”。
中國有句古語:術業有專攻,正是MoE模型的最直接的工作設計思路,即把任務分門別類,交由不同的“專家”進行解決。
如果說稠密(Dense)模型是個“全才”模型,旨在培養一個精通各個領域、能解決多個問題的“諸葛亮”,那么混合專家(MoE)模型則是個“專才”模式,側重于培養多個“臭皮匠”(即“專家”),配合著以更專業、更高效的團隊模式解決各種問題。
圖片來源:《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》
由此便不難理解為什么MoE模型會如此火爆。因為,培養一個“諸葛亮”所需要消耗的資源、成本都太高了,甚至慢慢地超出了普通企業的承受范圍。根據計算,訓練一個5000億參數規模的Dense模型,基礎算力設施投入約10億美金,無故障運行21個月,電費約5.3億元——這是現階段無法接受的算力投入。
那么,“三個臭皮匠”不僅能“頂個諸葛亮”,同時培養“三個臭皮匠”所需要的資源和成本可比培養“諸葛亮”可就相對簡單多了。像源2.0-M32在處理邏輯、代碼生成、知識等方面的能力是可以對標Llama3-700億的,但其所需要但推理算力卻低了一個量級,只有Llama3-700億的十九分之一。
相當的智能水平,但算力投入卻大幅減少,這也就意味著通過模算效率的提升,我們完全可以用更少的算力投入產出更智能的模型。這會是未來解決算力挑戰的一個關鍵思路,MoE模型的大火,所帶來的是一個AI行業解題思路的大轉變。
二、算法層面的優化:三個“臭皮匠”的搭配和配合是一門藝術。
雖說“三個臭皮匠,頂個諸葛亮”,但是這“三個臭皮匠”如何選擇、搭配以及配合處理任務,恰恰才是其“頂個諸葛亮”的根本。
更直觀的對比,以古代作戰為例,同樣是一群人打架,為什么散兵游勇很難和正規軍進行對抗、戰斗?其根本在于正規軍有專業的兵種搭配和配合,也就是“兵法”的輔助。放到AI領域,算法即“兵法”。
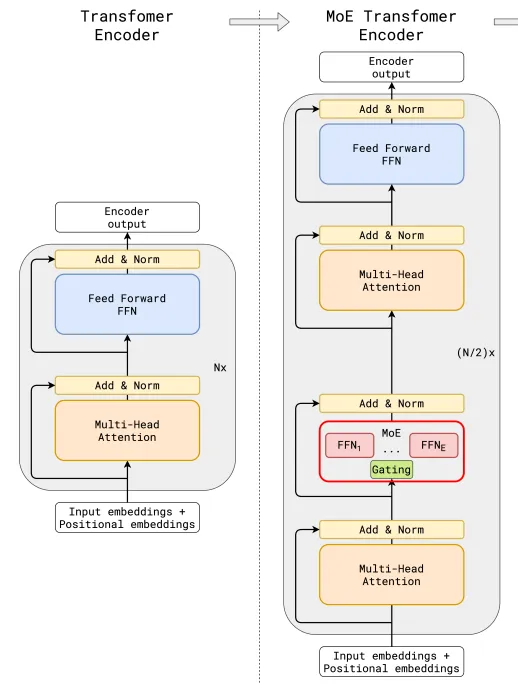
在MoE模型上,雖說核心思路是一致的,但是關于門控網絡的位置、模型、專家數量、以及MoE與Transformer架構的具體結合方案,各家方案都不盡相同,由此將拉開各家MoE模型在應用上的差距。
比如,在算法層面,源2.0-M32就提出并采用了一種新型的算法結構:基于注意力機制的門控網絡(Attention Router)。針對MoE模型核心的專家調度策略,這種新的算法結構更關注專家模型之間的協同性度量,有效解決傳統門控網絡下,選擇兩個或多個專家參與計算時關聯性缺失的問題,使得專家之間協同處理數據的水平大為提升。
同時,源2.0-M32采用了源2.0-2B為基礎模型設計,由此得以沿用并融合局部過濾增強的注意力機制(LFA, Localized Filtering-based Attention),通過先學習相鄰詞之間的關聯性,然后再計算全局關聯性的方法,能夠更好地學習到自然語言的局部和全局的語言特征,對于自然語言的關聯語義理解更準確,進而提升了模型精度。

基于注意力機制的門控網絡(Attention Router)
在MoE模型中,算法層面的優化將是模算效率提升的一個很好補充。簡單來說,“三個臭皮匠”,能基于算法優化而發揮出更大的價值,在處理問題上得到更好的反饋。這或許也是接下來各家MoE模型進一步拉開差距的關鍵。
三、數據需求的延續:“諸葛亮”和“臭皮匠”都需要高質量的數據投喂。
這一點毋庸置疑,“諸葛亮”和“臭皮匠”同屬于“人”,其成長的根本在于高質量知識的吸收。同樣的,MoE模型和Dense模型也都同屬于AI模型,都需要高質量的數據投喂,數據質量越高,對應產出的模型精度越高。
為什么源2.0-M32在代碼生成、代碼理解、代碼推理、數學求解等方面有著出色的表現,其根本在于數據質量。源2.0-M32基于2萬億的token進行訓練,覆蓋萬億量級的代碼、中英文書籍、百科、論文及合成數據。其中,大幅擴展代碼數據占比至47.5%,從6類最流行的代碼擴充至619類,并通過對代碼中英文注釋的翻譯,將中文代碼數據量增大至1800億token。
總的來說,培養“臭皮匠”與培養“諸葛亮”所需要的資源并沒有太多本質上的區別,只是培養的思路、方法有所優化,從而使得我們能用更少的資源、成本就培養出了一個能相當甚至是超過“諸葛亮”的“臭皮匠”智囊團。由此,MoE模型成了各大廠商爭先布局的重要方向。
MoE模型普及的關鍵,仍需要解決最核心的算力問題
正如前面所說,MoE模型和Dense模型同屬于AI,在發展需要上并沒有太大的本質區別。因此,長期以來困擾AI發展的算力問題如算力太貴、算力供給不足、算力資源不平衡、算力利用率低等,還是MoE同樣面對的,甚至是其走向大眾市場的一個明顯阻礙。
浪潮信息在發布源2.0-M32大模型時,吳韶華就提到,“這個模型我們在研發的初衷就是為了大幅提升基礎模型的模算效率,在這里面有兩個層面,一方面是提升它的精度,另一方面是降低同等精度水平下的算力開銷。”
現如今,很多企業對MoE模型的重視大多聚焦模型能力,殊不知算力開銷也是一個重要考量。若能花更少的算力,辦更多的事情,那么對于MoE模型而言將是普及的關鍵。
目前,源2.0-M32大幅提升了模型算力效率,在實現與業界領先開源大模型性能相當的同時,顯著降低了在模型訓練、微調和推理所需的算力開銷。

源2.0-M32業界主流評測任務表現
其中,在模型推理運行階段,源2.0-M32處理每token所需算力僅為7.4Gflops,而LLaMA3-70B所需算力則為140Gflops。在模型微調訓練階段,同樣是對1萬條平均長度為1024 token的樣本進行全量微調,源2.0-M32消耗算力約0.0026PD(PetaFLOPs/s-Day),而LLaMA3消耗算力約為0.05PD。
目前,源2.0-M32的激活參數為37億,但是卻取得了和700億參數LLaMA3相當的性能水平,而所消耗算力僅為LLaMA3的1/19。如此大幅提升的模算效率,將為企業開發應用生成式AI提供一條“模型高性能、算力低門檻”的優質路徑。
根據浪潮信息透露,源2.0-M32開源大模型配合企業大模型開發平臺EPAI(Enterprise Platform of AI),將助力企業實現更快的技術迭代與高效的應用落地。也就是說,在技術層面,MoE模型將加速普及,而在應用層面,源2.0-M32所提升的模算效率,對模型能力和算力開銷兩大問題的解決將進一步加速生成式AI的普及應用,讓更多企業都能享受到AI的時代紅利。
寫在最后
MoE模型并非人工智能技術前進的終點,更不是大模型發展的最終形態。但是,它的出現著實是改變了AI發展的路徑,讓AI落地有了更清晰的方向。
今天,大模型迫切地需要變得越來越大,但是單純的變大并不能解決行業問題,大模型更應該想清楚如何變得越來越有用。“有用”是一個復雜的概念,既需要模型能力夠強,也需要算力開銷夠小,讓企業用得起、用得好。
浪潮信息所強調的模算效率就旨在解決這兩大問題。事實上,從源2.0-M32的發布來看,模算效率的提升確實把MoE模型推向了一個更廣泛的發展階段,我們甚至能在此看到不同行業、不同企業都能用上、用好MoE模型的可能。
*本文圖片均來源于網絡
#智能相對論 Focusing on智能新產業新服務,這是智能的服務NO.264深度解讀
此內容為【智能相對論】原創,
僅代表個人觀點,未經授權,任何人不得以任何方式使用,包括轉載、摘編、復制或建立鏡像。
部分圖片來自網絡,且未核實版權歸屬,不作為商業用途,如有侵犯,請作者與我們聯系。
?AI產業新媒體;
?澎湃新聞科技榜單月度top5;
?文章長期“霸占”鈦媒體熱門文章排行榜TOP10;
?著有《人工智能 十萬個為什么》
?【重點關注領域】智能家電(含白電、黑電、智能手機、無人機等AIoT設備)、智能駕駛、AI+醫療、機器人、物聯網、AI+金融、AI+教育、AR/VR、云計算、開發者以及背后的芯片、算法等。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
